Parsing Prolog with Pidgin
Happy birthday to my sister! This is part of a series of posts about implementing a miniature Prolog interpreter in C#.
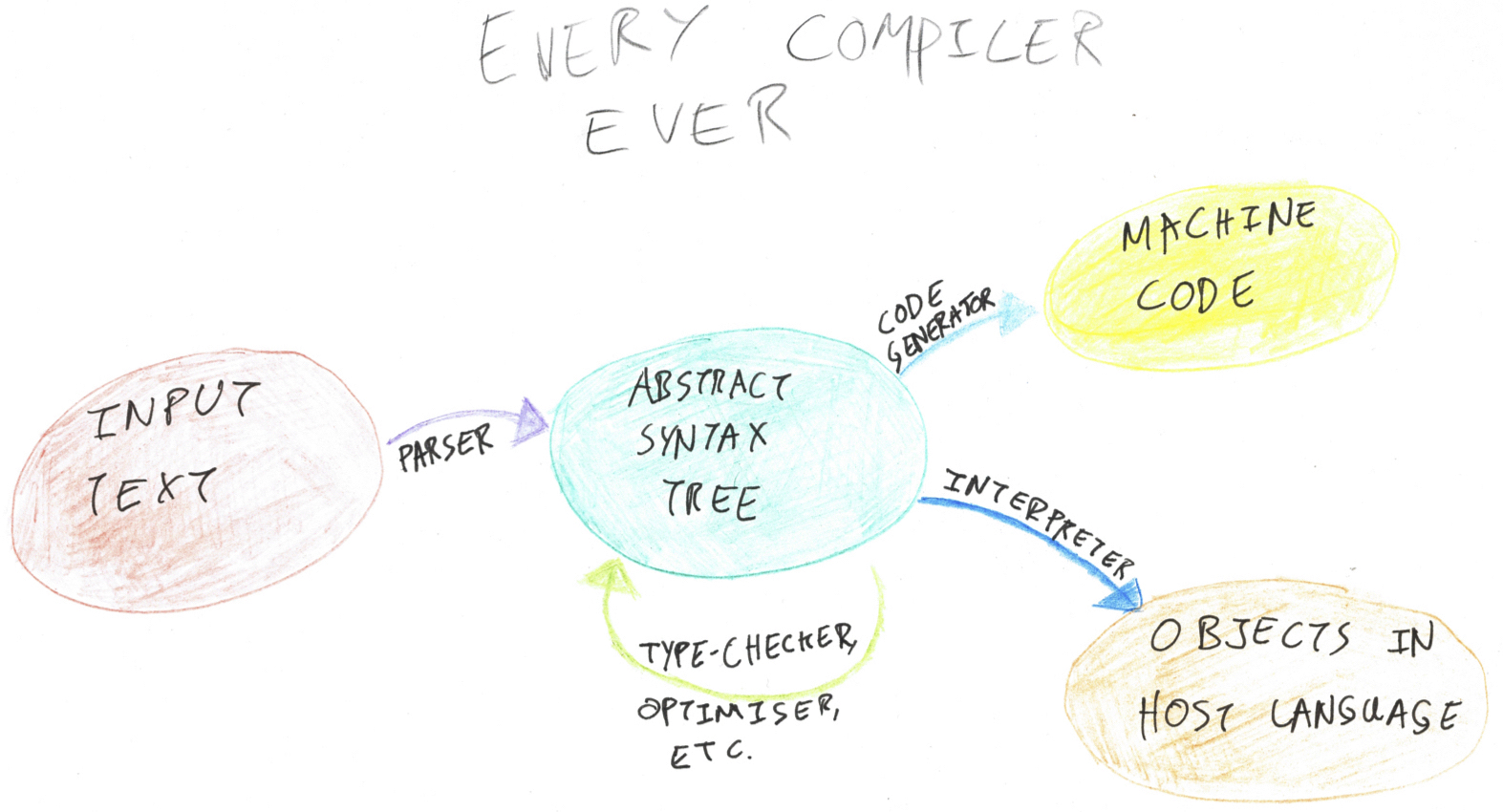
In this post I’m going to focus on the left-hand part of that diagram. We’ll use my parsing library Pidgin to convert Prolog source code into the abstract syntax classes I outlined in the previous post.
About Pidgin
Pidgin is a parser combinator library, meaning it consists of three things:
- A type
Parser<TToken, T>, representing a process which consumes a sequence ofTTokens and produces aT. (In our case,TTokenwill becharbecause we’re parsing textual data from a string.) - Methods to create simple
Parsers, such as “consume a single character”. - Methods to combine
Parsers into more complex and interesting ones, such as “run two parsers sequentially”.
The power of parser combinators comes from the fact that parsers are treated as ordinary values. You can pass them around as parameters, return them, store them in fields… Programming with parser combinators is just programming. Contrast this with “language workbench” tools like Antlr, which are often more powerful than parser combinators but have a separate syntax, toolchain, etc. Parser combinators are great for medium-sized parsing tasks like this one.
It’s worth elaborating a bit on what I mean by “consume a sequence”. A parser walks left to right along an input sequence, keeping track of its location in the input. Consuming a token means moving the “current location” pointer along to the next token. This is much like how the Stream classes work in .NET — calling a stream’s Read method moves the stream’s current position, so that successive calls to Read return different results. (Pidgin indeed lets you feed a Stream to a Parser.)
When a parser makes a decision about what to do next, that decision is based only on the current character and not on what comes next. If the parser moves further along the string and then realises that decision was wrong, it has to backtrack to the position where it made the decision before it can proceed with a different choice. Backtracking can be catastrophically costly (as described in a short talk by my esteemed ex-colleague Balpha), so you want to code your parser to minimise the amount of backtracking it might have to do. With Pidgin, backtracking is disabled by default; it’s enabled by the Try function.
Handling Tokens and Whitespace
Let’s start with the basics and build upwards. Prolog is a whitespace-insensitive language, so we need a way to skip over the whitespace in the source code. We’ll use a convention where each component Parser will consume any whitespace after parsing any relevant non-whitespace characters.
Here’s a method which creates a Parser which consumes a specific character, skips over any whitespace, and then returns the original character.
static Parser<char, char> Tok(char value) // for "token"
=> Char(value).Before(SkipWhitespaces);(Char comes from the Pidgin.Parser static class; all of today’s code is in a file with using static Pidgin.Parser and using static Pidgin.Parser<char> at the top.) Char is a parser which matches a specific character; SkipWhitespaces greedily consumes and discards a sequence of whitespace characters; and Before glues two parsers together sequentially, keeping only the result of the first one. So Tok('(') will match the input strings "(" and "( " but not " (" or ")".
Here’s an equivalent parser for a specific string:
static Parser<char, string> Tok(string value)
=> Try(String(value)).Before(SkipWhitespaces);Why am I using the backtracking function Try here? Remember, a parser consumes its input one character at a time, and makes decisions based only on the current character. If the first character of the input looks like it matches value, Pidgin will commit to running the String(value) parser; if matching the string fails after the first character then the parser needs to return to where it was so that it can try any alternative ways to parse from that location.
For an example of why we need Try, consider the parser String("prolog").Or(String("programming")). Or is Pidgin’s choice function — it attempts to run one parser, and falls back on the other one if the first parser failed without consuming any input. Here’s our parser represented pictorally:
+--Or--+
| |
String("prolog") String("programming")
Let’s think about how this parser behaves when you feed it the string "programming". Naïvely we might expect this to succeed, because String("programming") is one of Or’s options. But in fact this parser will fail to parse the string "programming". Looking at it step by step reveals why:
At the start of the parsing process, the current character is the first letter, namely p.
p r o g r a m m i n g
Our Or parser will try to apply the prolog parser first. The prolog parser looks at the current character and says “This looks like the start of prolog to me. I’ll consume it.”
p r o g r a m m i n g
This continues for a couple more characters.
p r o g r a m m i n g p r o g r a m m i n g
Now that we’re looking at a g, it’s clear that the input doesn’t match the string prolog. The prolog parser fails and yields control back to Or. Because the prolog parser consumed input and did not backtrack, Or will not attempt to apply the programming parser. (If it did try, it would fail anyway because we’re no longer looking at a p.) If the prolog parser were wrapped in a Try, it would have backtracked to the p upon failing, allowing Or to fall back on the programming parser.
It’s common to use Try for each word and symbol in your language’s grammar; I’m going to use Tok for each of my low level component parsers.
Finally, we can generalise these Tok methods to run an arbitrary Parser with backtracking and whitespace.
static Parser<char, T> Tok<T>(Parser<char, T> p)
=> Try(p).Before(SkipWhitespaces);
static Parser<char, char> Tok(char value) => Tok(Char(value));
static Parser<char, string> Tok(string value) => Tok(String(value));I have a half-baked plan to add this Tok parser, along with some other tools for handling whitespace, to the Pidgin library itself, so you don’t have to write it yourself every time you write a parser.
Some useful token parsers for Prolog:
static readonly Parser<char, char> _comma = Tok(',');
static readonly Parser<char, char> _openParen = Tok('(');
static readonly Parser<char, char> _closeParen = Tok(')');
static readonly Parser<char, char> _dot = Tok('.');
static readonly Parser<char, string> _colonDash = Tok(":-");Names
Prolog has two types of names — atoms start with a lowercase letter and variables start with an uppercase letter or an underscore.
static readonly Parser<char, string> _atomName = Tok(
from first in Lowercase
// OneOf is like Or, but it works with more than two parsers
from rest in OneOf(Letter, Digit, Char('_')).ManyString()
select first + rest
);
static readonly Parser<char, string> _variableName = Tok(
from first in Uppercase.Or(Char('_'))
from rest in OneOf(Letter, Digit, Char('_')).ManyString()
select first + rest
);One of the fun things about C#’s from...select syntax is that it’s duck-typed. The C# compiler allows you to use from...select with any object which has eligible Select and SelectMany methods, not just IEnumerable. Pidgin allows you to (ab)use this notation to sequence parsers — from x in p1 from y in p2 select f(x, y) is equivalent to p1.Then(p2, (x,y) => f(x,y)). So when you see a parser defined using from...select you should read it from top to bottom as a script.
ManyString takes a parser and greedily runs it in a loop, then packs all of that parser’s results into a string. Uppercase, Lowercase, Letter and Digit all consume and return a single character of their respective types.
So, taken as a whole, _atomName consumes and returns a string as long as it’s a valid Prolog atom. Here’s how it works:
- Consume a lowercase character and name it
first - Consume as many letters, digits and underscores as possible, naming the resulting string
rest - Skip any whitespace coming after the name (that’s what
Tokdoes) - Return the string
first + rest
_variableName works just the same, except in step 1 it consumes an uppercase letter or an underscore. Let’s de-duplicate them:
static Parser<char, string> Name(Parser<char, char> firstLetter)
=> Tok(
from first in firstLetter
from rest in OneOf(Letter, Digit, Char('_')).ManyString()
select first + rest
);Terms
Terms in Prolog have a recursive structure, as discussed previously. A predicate’s arguments can be any term, including another predicate. This circularity poses a problem for our parser code — the _predicate parser needs to call _term, but _term needs to call _predicate, so what order can you put the declarations in?
Pidgin’s built-in Rec function enables forward references like this. The idea is to use a lambda to delay the access to the field until after it’s been initialised.
static readonly Parser<char, Term> _term = Rec(() => OneOf(
_variable,
// upcast the Parser<char, Predicate> into a Parser<char, Term>
_predicate.Cast<Term>(),
_atom
)).Labelled("term");_predicate is textually below _term, so when _term is initialised _predicate will be null. By putting the _predicate reference inside a lambda and passing it to Rec, we can prevent _predicate from being accessed until after it’s been initialised. (Rec returns a parser which calls the lambda the first time it’s run.)
static readonly Parser<char, Term> _atom
= Name(Lowercase)
.Select(name => (Term)new Atom(name))
.Labelled("atom");
static readonly Parser<char, Term> _variable
= Name(Uppercase.Or(Char('_')))
.Select(name => (Term)new Variable(name))
.Labelled("variable");
static readonly Parser<char, Predicate> _predicate = (
from name in Try(Name(Lowercase).Before(_openParen))
from args in CommaSeparated(_term).Before(_closeParen)
select new Predicate(name, args)
).Labelled("predicate");
static Parser<char, ImmutableArray<T>> CommaSeparated<T>(Parser<char, T> p)
=> p.Separated(_comma).Select(x => x.ToImmutableArray());I’m using Try again in the _predicate parser. This is to disambiguate predicates from atoms. Both start in the same way (a lowercase letter) and you can’t be sure you’re parsing a predicate until you see a parenthesis. So our _term parser first attempts to read a predicate, but if it doesn’t see a parenthesis then it backtracks and reads the name as an atom instead. The order of OneOf’s arguments matters!
Rules, Queries and Whole Programs
We’re on the home straight. A Prolog program consists of a collection of top-level rules and facts. A rule consists of a predicate followed by the symbol :- and a comma-separated list of predicates, and ends with a . symbol. A fact is just a rule with no right-hand side.
static readonly Parser<char, Rule> _rule
= Map(
(head, body) => new Rule(head, body),
_predicate,
_colonDash
.Then(CommaSeparatedAtLeastOnce(_predicate))
.Or(Return(ImmutableArray<Predicate>.Empty))
)
.Before(_dot)
.Labelled("rule");
static Parser<char, ImmutableArray<T>> CommaSeparatedAtLeastOnce<T>(Parser<char, T> p)
=> p.SeparatedAtLeastOnce(_comma).Select(x => x.ToImmutableArray());(Map is another way of writing Then; Return is a parser which always returns the given value without touching the input string.) Note that .Or(Return(...)) is applied to the result of _colonDash.Then(...). If the parser encounters the :- symbol then it commits to reading at least one item in the rule’s body. name(args) :- . is not valid Prolog; if a programmer wants a rule with no body then they have to omit the :-.
Finally, a Prolog program consists of a sequence of rules. We’re also going to need a parser for individual queries typed at the interactive prompt.
static readonly Parser<char, ImmutableArray<Rule>> _program =
from _ in SkipWhitespaces
from rules in _rule.Many()
select rules.ToImmutableArray();
static readonly Parser<char, Predicate> _query = SkipWhitespaces.Then(_predicate);
public static ImmutableArray<Rule> ParseProgram(string input) = _program.ParseOrThrow(input);
public static Predicate ParseQuery(string input) = _query.ParseOrThrow(input);Since by convention each of our component parsers has been consuming whitespaces after the text they match, we need to remember to SkipWhitespaces at the start of the file.
That’s our whole parser! Less than 80 lines of code is not bad, I think. A quick test of our last example from the previous post:
static void Main(string[] args)
{
var program = PrologParser.ParseProgram(@"
last(cons(X, nil), X).
last(cons(X, Xs), Y) :- last(Xs, Y).
");
Console.WriteLine(string.Join("\n", program));
// prints out:
// last(cons(X, nil), X).
// last(cons(X, Xs), Y) :- last(Xs, Y).
}Here are a couple of exercises you might try:
- Extend this code to support numbers, building on the exercise from the end of the last post.
- Extend this code to support lists.
- Prolog’s lists are linked lists;
[]is an empty list and cons cells look like[head | tail]. (headandtailare both arbitrary terms; though at runtimetailshould be a list.) - At first you can try pretending that lists are syntactic sugar — desugar
[]to anilatom and[head | tail]to acons(head, tail)predicate. - How can you avoid clashing with mentions of those names in user code?
- You could try mangling the names to something which can’t be typed by a user.
- You could try making them reserved words (adjust the parser to reject user-defined mentions of
consandnil). - You could try adding lists directly to the
TermAST.
- Prolog’s lists are linked lists;
- Try using Pidgin’s
CommentParserclass to handle Prolog code with comments in.
You can find this code in the example repo, in the file Parser.cs. Next time we’ll talk about unification, the core of Prolog’s bi-directional programming model. We’ll be using Sawmill to implement unification generically, without making any assumptions about Prolog’s syntax.